
Introduction
Materials and Methods
한우 안면 기반 개체 인식 프레임워크
데이터 수집
학습 데이터 구성
얼굴 검출 및 특징 추출 모델
메트릭 러닝 기반 특징 공간 학습 및 대표 특징 기반 개체 식별
신규 개체 등록을 위한 특징 갱신 조건
모델 학습 방법
개체 식별 및 신규 개체 등록 성능 평가
대표 시점 구성별 성능 평가
Results and Discussion
초기 개체 식별 모델 학습 결과
대표 시점 구성에 따른 신규 개체 등록 성능
오분류 사례 및 원인 분석
Conclusion
Introduction
국내 소고기 총 공급량은 전년 대비 1.8% 증가한 약 78만 톤으로 나타났으며, 1인당 소비가능량은 전년 대비 2.0% 증가한 15.2 kg으로 조사된다. 반면 국내 소고기 자급률은 40.1% 수준이며, 2026년 국내산 소고기 생산량은 도축 마릿수 감소로 인해 전년 대비 7.9% 감소한 28만 8천 톤으로 전망된다(KREI, 2026). 증가하는 소고기 소비 수요에 비해 국내산 소고기의 생산 여건은 제한적이므로, 생산성 향상과 효율적인 사육 관리가 요구된다. 특히 최근에는 소비자의 영양, 건강 및 식품 안전성에 대한 소비자의 관심이 높아짐에 따라 생산량 확보뿐만 아니라 개체별 상태를 지속적으로 확인하고 이를 사양관리에 반영할 수 있는 개체 단위의 정밀 관리가 요구된다(KREI, 2026; Berckmans, 2017). 이러한 관리를 수행하기 위해서는 동일한 사육 공간에 존재하는 여러 개체를 안정적으로 구분하고, 수집된 정보를 해당 개체와 정확하게 연결하는 개체 식별이 선행되어야 한다(Norton et al., 2019; Mahmud et al., 2021).
기존 축산 현장에서는 귀표, 목걸이형 센서 및 RFID (Radio-Frequency Identification)와 같은 표식·착용형 장치를 이용하여 개체를 식별하고 있다. 이러한 방식은 개체 식별 번호와 관리 정보를 직접 연결할 수 있다는 장점이 있으나, 장치의 부착과 유지 관리를 위해 작업자의 지속적인 개입이 요구된다. 또한 장치의 탈락, 훼손 및 재부착에 따른 추가 작업이 발생할 수 있어, 입식과 출하가 반복되는 환경에서는 관리 부담이 증가한다(Awad, 2016). 특히 관리 대상 개체가 지속적으로 변화하는 환경에서는 장치 기반 식별 방식의 운영 효율성이 저하될 수 있어 개체 단위 관리를 효율적으로 수행하기 위해서는 작업자의 개입과 장치 부착에 대한 의존성을 줄일 수 있는 비접촉식 개체 식별 기술이 필요하다(Andrew et al., 2021).
최근 컴퓨터 비전과 딥러닝 기술의 발전에 따라 다양한 생체 특징을 활용한 가축 개체 식별 연구가 수행되고 있으며, 비문, 체표 무늬 및 안면 이미지를 이용한 비접촉식 식별 방법이 제안되고 있다(Kyaw et al., 2025; Kang and Oh, 2025; Li et al., 2024; Xu et al., 2022). 예를 들어 젖소에서는 개체별 흑백 체표 무늬가 비교적 뚜렷하게 나타나기 때문에 체표 무늬 기반 개체 식별 연구가 수행되었으며(Andrew et al., 2021), 돼지에서는 안면 이미지를 이용한 딥러닝 기반 개체 인식 및 open-set 인식 연구가 제안되었다(Wang et al., 2023; Ma et al., 2025). 한우를 대상으로도 비문 패턴 또는 안면 이미지를 이용한 개체 식별 연구가 보고되었으나(Lee et al., 2023; Meng et al., 2023), 한우는 체색이 비교적 균일하고 개체 간 안면 외형의 차이가 작아 젖소의 체표 무늬와 같이 시각적으로 뚜렷한 특징에 의존하기 어렵다. 따라서 한우 안면 기반 개체 식별은 유사한 외형을 가진 개체들 사이에서 눈, 코, 이마 및 안면 윤곽과 같은 미세한 안면 특징을 안정적으로 학습해야 한다는 점에서 기존의 다른 가축 대상 개체 식별 연구와 구별된다. 또한 실제 축산 현장에서는 입식과 출하가 반복되므로, 식별 시스템은 기존 개체를 구분하는 기능뿐만 아니라 학습 단계에 포함되지 않은 신규 개체를 소수의 등록 이미지로 추가할 수 있어야 한다. 이러한 문제는 적은 수의 이미지로 새로운 개체의 특징을 표현하는 few-shot registration과, 기존에 학습된 표현을 유지하면서 새로운 클래스를 반영하는 incremental learning 관점과 연결된다(Shojaeipour et al., 2021; Li and Hoiem, 2018; Masana et al., 2023). 본 연구는 기존 개체에 대해 학습된 한우 안면 특징 공간을 기반으로 신규 개체의 대표 특징을 구성하고, 이를 Representative-feature database에 추가하여 식별 대상에 반영하는 구조를 평가하였다는 점에서 기존의 고정 개체 중심 식별 연구와 차별성을 가진다.
따라서 본 연구에서는 한우 안면 이미지를 이용한 딥러닝 기반 안면 인식 기술을 제안하였으며, 학습에 포함되지 않은 신규 개체에 대해 소수의 등록 이미지를 이용한 식별 가능성을 평가하였다. 이를 위해 실제 한우 농장에서 수집한 데이터를 통해 제안 기술의 성능을 평가하였으며, 현장 적용성을 검증하였다.
Materials and Methods
한우 안면 기반 개체 인식 프레임워크
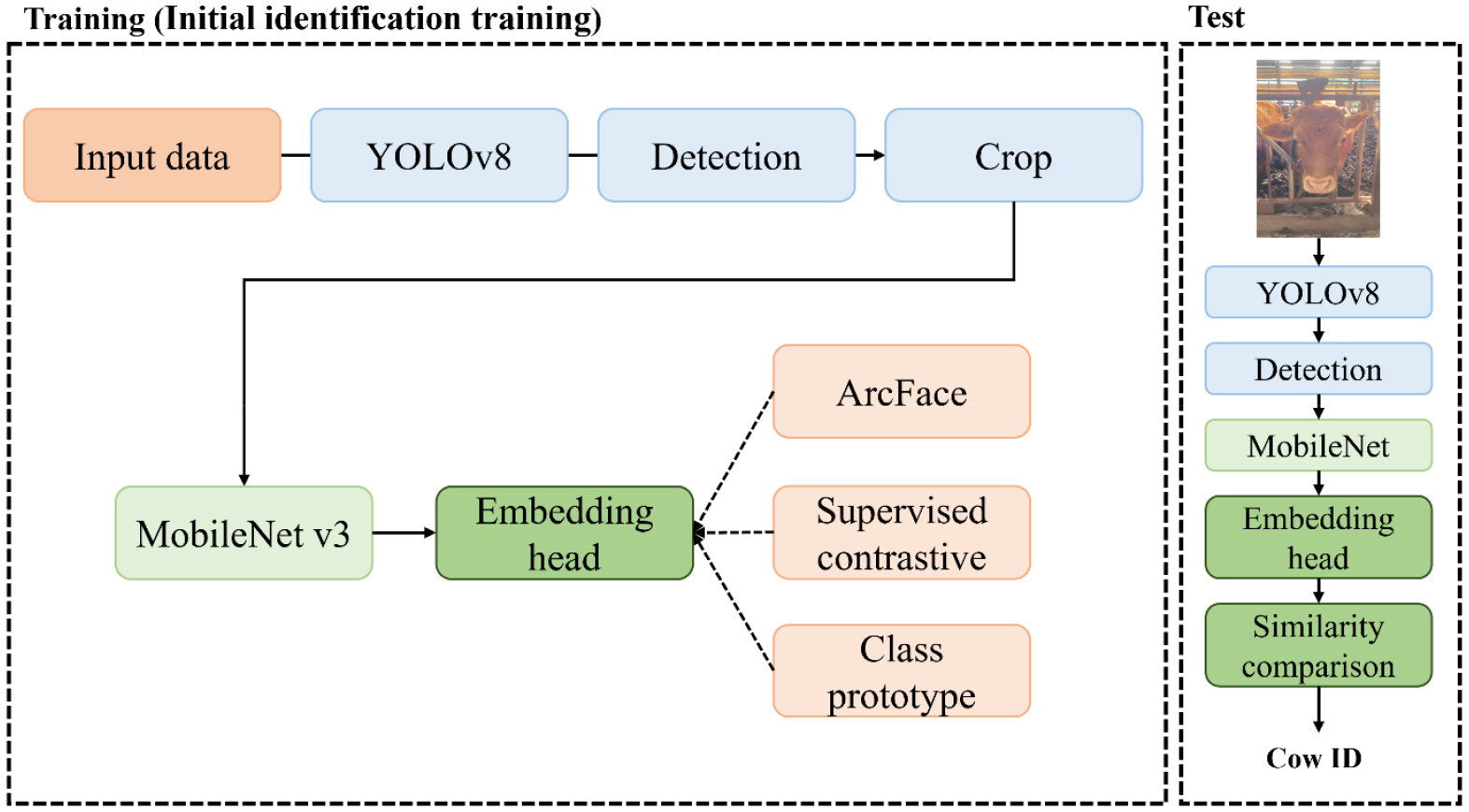
본 연구에서는 소 안면 이미지를 이용하여 기존 개체와 신규 개체를 통합적으로 식별할 수 있는 개체 인식 프레임워크를 제안한다. 전체 프레임워크는 얼굴 검출, 안면 특징 추출, 메트릭 러닝(Metric learning) 기반 임베딩 공간 구성, 개 체별 대표 특징 등록 및 유사도 기반 식별 단계로 구성하였으며, 프레임워크 예시는 Fig. 1에 제시하였다.
입력 이미지에서 소 얼굴 영역을 검출하고, 검출된 얼굴 이미지에서 고정된 차원의 특징 벡터를 추출하였다. 특징 추출 모델은 동일 개체의 안면 특징은 가깝게 표현하고 서로 다른 개체의 안면 특징은 구분할 수 있도록 학습하였다. 동일 개체의 여러 등록 이미지에서 추출한 특징 벡터의 평균을 해당 개체의 대표 특징으로 정의하고, 이를 개체별 대표 특징 데이터베이스에 저장하였다. 새로운 이미지가 입력되면 입력 이미지의 특징과 데이터베이스에 저장된 대표 특징 간 코사인 유사도를 비교하고, 가장 높은 유사도를 갖는 개체를 최종 식별 결과로 결정하였다.
전체 72마리의 한우 중 촬영 순서에 따라 ID 1-72를 부여하였다. 이 중 ID 1-40은 기본 식별 모델을 구축하기 위한 기존 개체로 설정하였으며, ID 41-72는 신규 개체 등록 실험에 사용하였다. 기본 식별 모델은 기존 개체 40마리의 안면 이미지로 학습하였다. 이후 신규 개체가 추가되는 상황을 반영하기 위해 신규 개체 등록을 위한 특징 갱신 조건을 적용하였으며, 갱신된 특징 추출 모델을 이용하여 신규 개체의 등록 이미지에서 산출한 대표 특징을 데이터베이스에 추가하였다. 이를 통해 기존 개체 정보를 유지하면서 신규 개체를 식별 대상에 반영하였다.
데이터 수집
한우 영상 데이터는 충청남도 청양에 위치한 충남대학교 동물자원연구센터(36.377872, 126.948131)에서 수집하였다. 촬영에는 스마트폰 3종(Iphone 13 mini, Apple, CA, USA; Iphone 11, Apple, CA, USA; HUAWEI P30 pro, Huawei, GD, China)을 사용하였다. 영상은 총 72마리의 한우를 대상으로 수집하였다. 촬영은 동일한 날짜에 오전, 정오 및 저녁 시간대로 구분하여 수행하였으며, 각 촬영은 해당 시간대의 급이 전에 진행하였다. 한우가 급이대 주변에서 머리를 내민 상태에서 축사 통로 앞에서 정지하여 개체별 안면 영상을 취득하였다. 촬영은 작업자가 스마트폰을 1.5 m 높이에서 들고 수행하였다. 촬영 거리는 별도의 고정 값으로 설정하지 않았으나, 한우 안면부가 카메라 시야각 내에서 화면의 약 40% 내외를 차지하도록 촬영 위치를 조정하였다. 이를 통해 현장 촬영 조건의 유동성을 유지하면서도 개체 식별에 필요한 안면 영역이 일정 수준 이상 확보되도록 하였다. 촬영 시간대에 따라 자연광과 축사 내부 조명 조건이 달라졌으며, 이에 따라 수집 영상에는 서로 다른 밝기 조건이 포함되었다. 신규 개체 등록 실험에 사용한 32마리는 오전과 정오 촬영 영상 외에 저녁 시간대 영상을 추가로 수집하였다. 본 연구에서는 실제 축산 환경에서 발생할 수 있는 영상 조건의 변화를 반영하기 위해 촬영 장비, 촬영 거리 및 촬영 각도를 일정하게 고정하지 않았다. 이에 따라 수집 영상에는 조명과 배경 조건의 차이, 안면 방향 변화 및 개체 움직임에 따른 부분 가림이 포함되었다. 개별 영상의 재생 시간은 약 1분이었으며, 총 176개의 영상을 수집하였다. 촬영 환경과 수집 영상의 예시는 Fig. 2에 제시하였다.

학습 데이터 구성
연속된 프레임에서 유사한 자세와 배경이 반복적으로 포함되는 것을 줄이기 위해, 총 176개의 영상으로부터 약 2초 간격으로 프레임을 추출하여 총 5,560장의 이미지를 구축하였다. 추출한 이미지 중 프레임 경계에 의해 과도하게 잘렸거나, 개체의 움직임으로 인해 안면 특징을 구분하기 어려운 이미지 3장은 분석에서 제외하였다. 본 연구에서는 육안으로 개체 식별이 가능한 5,557장의 이미지를 유효 데이터로 포함하였으며, 개체군별 이미지 구성은 Table 1에 제시하였다.
구축한 이미지는 소 얼굴 검출 모델과 개체 식별 모델의 학습 목적에 따라 서로 다른 형태로 구성하였다. 얼굴 검출 데이터는 원본 이미지와 소 얼굴 영역의 경계 상자(Bounding box, bbox) 좌표로 구성하였다. 소 얼굴 영역은 LabelImg를 이용하여 수동으로 주석하였으며(Tzutalin, 2015), 전체 5,557장의 이미지를 얼굴 검출 모델 학습용 3,890장과 평가용 1,667장으로 7:3 비율로 구분하였다. 유효 이미지 및 얼굴 영역 라벨링의 예시는 Fig. 3에 제시하였다.
Table 1.
Number of cattle and images used in this study
| Cattle ID | Number of cattle | Number of images | ||
| Extracted images | Excluded images | Valid images | ||
| ID 1-40 | 40 | 2,520 | 2 | 2,518 |
| ID 41-72 | 32 | 3,040 | 1 | 3,039 |
| ID 1-72 | 72 | 5,560 | 3 | 5,557 |

개체 식별 데이터는 얼굴 검출 데이터와 별도의 원본 이미지 집합으로 구성한 것이 아니라, 동일한 이미지에서 소 얼굴 영역을 추출한 뒤 개체별 ID에 따라 분류하여 구성하였다. 전체 72마리의 한우에는 촬영 순서에 따라 ID 1-72를 부여하였다. 이 중 ID 1-40은 기본 식별 모델 학습에 사용하는 기존 개체로 설정하였으며, ID 41-72는 초기 학습에 포함되지 않은 신규 개체로 설정하고, 등록 이미지 기반 식별 가능성을 평가하는 데 사용하였다. 동일 영상에서 연속적으로 추출된 프레임은 시각적으로 유사하므로, 기존 개체 ID 1-40의 데이터는 시간 순서에 따라 영상 구간을 분리하여 학습, 검증 및 평가 데이터로 구분하였다. 전체 영상 구간 중 앞부분 56%는 학습 데이터, 중간 14%는 검증 데이터, 마지막 30%는 평가 데이터로 사용하였다. 신규 개체 ID 41-72 데이터는 등록 후보 데이터와 평가 데이터로 구분하였다. 각 신규 개체의 영상 구간 중 앞부분 70%는 등록 후보 데이터로 사용하였으며, 나머지 30%는 평가 데이터로 고정하였다. 등록 이미지의 시점 구성, 등록 이미지 수에 따른 실험 조건은 모두 등록 후보 데이터에서 구성하였다. 평가 데이터는 등록 및 학습 과정에 사용하지 않고, 신규 개체 등록 이후의 식별 성능을 평가하는 데만 사용하였다. 데이터셋의 전체 구성과 분할 과정은 Fig. 4와 같다.

얼굴 검출 및 특징 추출 모델
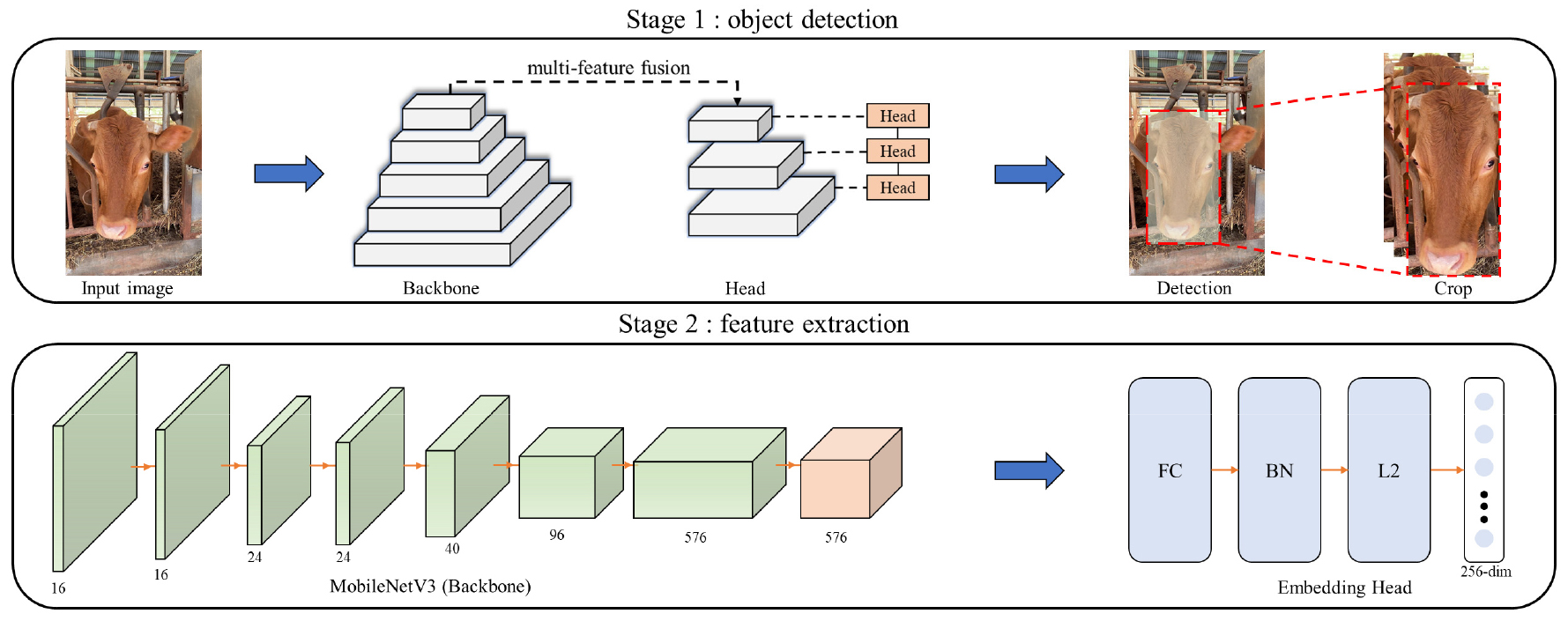
입력 이미지에서 소 얼굴 영역을 자동으로 추출하기 위해 YOLO (You only look once) v8 기반 객체 검출 모델을 사용하였다(Jocher et al., 2023). 얼굴 검출 모델은 입력 이미지에서 소의 안면 영역에 해당하는 Bbox를 추정하였다. 검출된 얼굴 영역은 원본 이미지에서 추출한 뒤, 개체 식별 모델의 입력 이미지로 사용하였다. 이를 통해 배경, 축사 구조물 및 신체 일부와 같이 개체 식별과 직접적인 관련이 낮은 정보를 제거하고 안면 특징을 중심으로 학습하고자 하였다.
개체 식별 모델은 MobileNet V3 기반의 특징 추출 네트워크와 임베딩 헤드로 구성하였다. MobileNet V3는 적은 연산량으로 이미지 특징을 추출할 수 있는 경량 백본(Backbone)으로, 향후 축사 내부의 엣지 컴퓨팅 장치에서 개체 식별을 수행할 수 있는 구조를 고려하여 특징 추출 모델로 사용하였다. 입력 얼굴 이미지는 192 × 192로 변환한 뒤 MobileNet V3 백본을 통과하였다. 추출된 특징은 임베딩 헤드를 통해 256 차원의 특징 벡터로 변환하였으며, 특징 벡터 간 코사인 유사도(Cosine similarity)를 계산할 수 있도록 L2 정규화(L2 normalization)를 적용하였다. 식별 모델의 구조는 Fig. 5에 제시하였다.
메트릭 러닝 기반 특징 공간 학습 및 대표 특징 기반 개체 식별
본 연구에서는 한우 개체별 안면 차이를 특징 벡터로 표현하기 위해 메트릭 러닝(Metric learning)을 적용하였다. 메트릭 러닝은 이미지 간 특징 거리를 학습하여, 동일한 대상의 특징은 가깝게 배치하고 서로 다른 대상의 특징은 구분되도록 특징 공간을 구성하는 방법이다. 본 연구에서 하나의 클래스(Class)는 하나의 한우 개체 ID를 의미하며, 각 이미지에는 촬영 대상 한우의 ID를 클래스 라벨로 부여하였다.
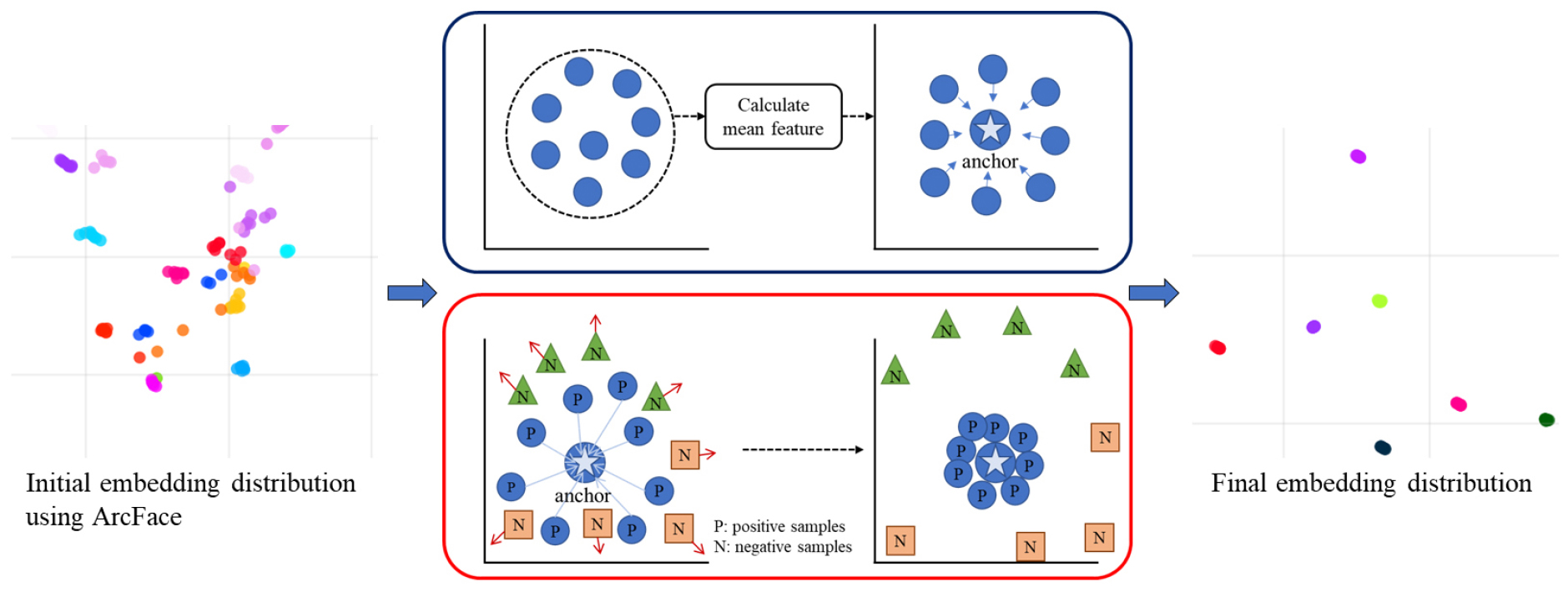
한우 안면 이미지는 동일한 개체라도 촬영 시점, 얼굴 방향, 밝기 및 부분 가림에 따라 서로 다르게 나타날 수 있다. 반면 서로 다른 한우는 체색과 전체적인 외형이 유사하므로, 개체 간 미세한 안면 차이를 구분해야 한다. 이러한 특성을 고려하면 단순히 각 이미지를 개체 ID로 분류하는 것만으로는 촬영 조건 변화에 대응할 수 있는 특징 공간을 구성하기 어렵다. 따라서 본 연구에서는 개체 간 구분 성능과 동일 개체 내 특징의 일관성을 함께 확보하기 위해 ArcFace loss, SupCon loss (Supervised contrastive loss) 및 Class-prototype loss를 결합하여 특징 추출 모델을 학습하였다.
ArcFace loss는 각 클래스에 대응하는 가중치 벡터와 입력 이미지의 특징 벡터를 정규화한 뒤, 두 벡터 사이의 각도를 기준으로 클래스를 구분하는 손실 함수이다. 일반적인 분류 손실은 정답 클래스를 맞히는 방향으로 모델을 학습하지만, 서로 다른 클래스 사이의 특징 거리가 충분히 확보되는지는 직접적으로 제어하지 않는다. ArcFace loss는 정답 클래스에 각도 마진(Angular margin)을 추가하여, 입력 이미지의 특징이 해당 클래스의 방향에 더 가깝게 위치하도록 요구한다. 본 연구에서는 외형이 유사한 한우 개체 사이에서도 안면 특징이 구분될 수 있도록 개체 간 각도 간격을 확보하기 위해 ArcFace loss를 적용하였다.
SupCon loss는 하나의 배치에 포함된 이미지 간 관계를 이용하여 특징 공간을 학습하는 손실 함수이다. 동일한 개체 ID를 갖는 이미지 쌍은 양성 쌍(Positive pair)으로 설정하고, 서로 다른 개체 ID를 갖는 이미지 쌍은 음성 쌍(Negative pair)으로 설정하였다. 학습 과정에서는 양성 쌍의 특징 거리가 가까워지고, 음성 쌍의 특징 거리는 멀어지도록 손실을 계산하였다. 이를 통해 동일 개체가 정면, 좌측면 또는 우측면으로 촬영되거나 밝기 조건이 달라지더라도, 해당 이미지의 특징이 동일한 개체를 나타내는 방향으로 배치되도록 하였다. ArcFace loss가 클래스 간 판별 경계를 형성하는 역할을 한다면, SupCon loss는 촬영 조건 변화에 따라 발생할 수 있는 동일 개체 내 특징 편차를 줄이는 역할을 한다.
Class-prototype loss는 각 클래스에 속하는 이미지의 평균 특징 벡터를 해당 클래스의 대표 특징으로 정의하고, 개별 이미지의 특징이 해당 대표 특징에 가까워지도록 유도하는 보조 손실이다. 본 연구에서 하나의 클래스는 하나의 한우 개체 ID이므로, Class prototype은 동일 개체의 이미지에서 추출한 특징 벡터의 평균을 의미한다. 개별 이미지의 특징과 Class prototype 사이의 거리를 손실로 반영함으로써, 동일 개체에 속하는 특징이 개체별 평균 특징을 중심으로 분포하도록 하였다. Class-prototype loss는 본 연구의 등록 기반 식별 구조를 학습 과정에 반영하기 위해 적용하였다. 신규 개체의 식별 단계에서는 클래스 내의 이미지에서 추출한 특징 벡터의 평균을 개체별 대표 특징으로 저장하고, 입력 이미지의 특징과 저장된 대표 특징 사이의 유사도를 비교하여 개체를 식별한다.
세 손실 함수인 ArcFace loss, SupCon loss, Class-prototype loss는 각각 서로 다른 개체 간 특징 방향의 분리를 유도하고, 다양한 촬영 조건에서도 동일 개체의 특징이 가깝게 배치되도록 하며, 개별 이미지의 특징이 개체별 평균 특징을 중심으로 분포하도록 한다. 본 연구에서는 세 손실을 Fig. 6과 같이 순차적으로 적용하여, 개체 간 특징을 구분하는 동시에 대표 특징 기반 등록 및 식별에 적합한 특징 공간을 구성하였다.
이와 같이 학습된 특징 공간을 기반으로, 본 연구에서는 동일 개체에 속하는 여러 등록 이미지의 특징을 하나의 대표 특징으로 표현하였다. 등록 이미지에서 추출된 특징 벡터의 평균을 해당 개체의 대표 특징 벡터로 정의하였으며, 대표 특징 벡터는 식 (1)과 같이 계산하였다.
Where is the representative feature vector of individual , is the set of registration images for individual , is the number of registration images, and is the embedding vector extracted from image by the feature extraction model.
입력 이미지의 특징과 개체별 대표 특징 간 유사도는 식 (2)와 같이 코사인 유사도를 이용하여 계산하였다. 입력 이미지에 대한 최종 개체 ID는 저장된 대표 특징 중 가장 높은 코사인 유사도를 갖는 개체로 결정하였다.
Where is similarity score, is the cosine similarity between the input image and individual , is the embedding vector extracted from the input image, and is the representative feature vector of individual.
신규 개체 등록을 위한 특징 갱신 조건
본 연구에서는 초기 학습에 포함되지 않은 신규 개체를 식별 대상에 추가할 수 있는지 평가하기 위해, 기존 개체 ID 1–40으로 학습된 초기 특징 추출 모델을 기반으로 신규 개체 ID 41–72의 등록 이미지를 반영하였다. 신규 개체 등록은 평가 대상 개체의 등록 이미지로부터 안면 특징 벡터를 추출하고, 이를 개체별 대표 특징으로 저장한 뒤, 평가 이미지와의 유사도를 비교하는 방식으로 수행하였다.
신규 개체 등록 과정에서 특징 추출 모델의 갱신 조건이 식별 성능에 미치는 영향을 확인하기 위해 두 가지 Feature-update 조건을 적용하였다. 첫 번째 조건은 Exemplar-assisted update로, 기존 개체의 일부 대표 이미지를 신규 개체 등록 이미지와 함께 사용하여 모델을 갱신하는 방식이다. 이 조건에서는 기존 개체의 특징 표현이 신규 개체 등록 과정에서 과도하게 변화하는 것을 줄이기 위해, 기존 개체별 대표 특징과 가까운 일부 이미지를 함께 학습에 포함하였다. 두 번째 조건은 Distillation-assisted update로, 이전 모델의 출력 및 특징 표현을 기준으로 사용하여 신규 개체 등록 과정에서 기존 모델이 학습한 표현이 크게 변하지 않도록 유도하는 방식이다. 본 연구에서는 두 조건을 신규 개체 등록을 위한 특징 갱신 설정으로 사용하였으며, 두 조건 간의 등록 이미지에 대한 시점 구성이 신규 개체 식별 성능에 미치는 영향을 중심으로 분석하였다.
각 Feature-update 조건에서 갱신된 특징 추출 모델을 이용하여 신규 개체의 등록 이미지로부터 256차원의 Embedding vector를 추출하였다. 동일 개체에 대해 여러 장의 등록 이미지가 사용된 경우, 각 이미지에서 추출된 Embedding vector의 평균을 계산하여 해당 개체의 Representative feature로 정의하였다. 이렇게 구성된 Representative feature는 개체 ID와 함께 Representative-feature database에 저장하였다.
평가 이미지가 입력되면 동일한 특징 추출 모델을 이용하여 평가 이미지의 Embedding vector를 추출하였다. 이후 평가 이미지의 Embedding vector와 Representative-feature database에 저장된 개체별 Representative feature 간 Cosine similarity를 계산하였다. 최종 예측 ID는 가장 높은 Cosine similarity를 갖는 Representative feature의 개체 ID로 결정하였다. 이를 통해 본 연구에서는 학습에 포함되지 않은 신규 개체가 소수의 등록 이미지만으로 식별 대상에 추가될 수 있는지를 평가하였다.
모델 학습 방법
얼굴 검출 모델, 초기 개체 인식 모델 및 신규 개체 등록을 위한 특징 갱신 모델의 세부 학습 조건은 Table 2에 제시하였다. 얼굴 검출 모델은 YOLO-v8n을 기반으로 구성하였으며, 원본 이미지에서 한우의 안면 영역을 검출하도록 학습하였다. 입력 이미지 크기는 640 × 640으로 설정하였고, 전체 100 Epoch 동안 학습하였다.
Table 2.
Training conditions
| Item | Face detection model | Initial identification model | Registration update model |
| Model | YOLO-v8n | MobileNet V3-Small | MobileNet V3-Small |
| Input size | 640 × 640 | 192 × 192 | 192 × 192 |
| Embedding dimension | - | 256 | 256 |
| Epochs | 100 | 100 | 25 for update |
| Batch size | 16 | 32 | 24 |
| Optimizer | Ultralytics auto optimizer | AdamW | AdamW |
| Learning rate | lr0=0.01, lrf=0.01 | Backbone: 0.0002, head: 0.0008 | Backbone: 0.00008, head: 0.0003 |
| ArcFace margin (m) | - | 0.35 | 0.35 |
| ArcFace scale (s) | - | 30.0 | 30.0 |
| SupCon temperature (τ) | - | 0.07 | 0.07 |
| Prototype-loss weight | - | 0.10 | 0.10 |
| Distillation-loss weight | - | - | Logit:1.0, feature: 0.2* |
| Distillation temperature | - | - | 2.0* |
| Exemplars per ID | 2** |
초기 개체 인식 모델은 기존 개체 ID 1–40의 안면 이미지를 이용하여 학습하였다. 특징 추출 백본에는 ImageNet 데이터셋으로 사전학습된 MobileNet V3-Small의 가중치를 초기값으로 사용하였으며, 한우 안면 이미지에 적합한 특징 표현을 학습하도록 모델 파라미터를 추가로 갱신하였다. 입력 얼굴 이미지는 192 × 192 크기로 변환하였고, Embedding head를 통해 256차원의 특징 벡터를 생성하였다. 초기 개체 인식 모델은 100 Epoch 동안 학습하였으며, Optimizer는 AdamW를 사용하였다. 학습률은 Backbone과 Embedding head에 서로 다르게 적용하였다.
신규 개체 등록 성능을 평가하기 위해, 초기 개체 인식 모델의 가중치를 기반으로 등록 갱신 모델을 구성하였다. 등록 갱신 모델은 초기 학습에 포함되지 않은 신규 개체 ID 41–72의 등록 이미지를 반영하기 위해 사용하였다. 이 과정에서는 신규 개체 등록을 위한 특징 갱신 조건절에서 설명한 Exemplar-assisted update와 Distillation-assisted update 조건을 적용하였으며, 각 조건에서 동일한 Backbone 구조와 Embedding dimension을 사용하였다. 등록 갱신 모델은 25 Epoch 동안 학습하였고, 초기 개체 인식 모델보다 낮은 Backbone learning rate를 적용하여 기존에 학습된 안면 특징 표현이 급격하게 변하지 않도록 하였다.
초기 개체 인식 모델과 등록 갱신 모델은 ArcFace loss, Supervised contrastive loss 및 Class-prototype loss를 함께 사용하여 학습하였다. ArcFace loss의 Margin과 Scale은 각각 0.35와 30.0으로 설정하였고, Supervised contrastive loss의 Temperature는 0.07로 설정하였다. Class-prototype loss의 가중치는 0.10으로 설정하였다. Distillation-assisted update 조건에서는 이전 모델의 출력 및 특징 표현을 유지하기 위해 Logit distillation loss와 Feature distillation loss를 추가로 적용하였으며, 각각의 가중치는 1.0과 0.2로 설정하였다. Distillation temperature는 2.0으로 설정하였다. Exemplar-assisted update 조건에서는 기존 개체별 대표 특징과 가까운 이미지 2장을 Exemplar로 사용하였다.
모델 학습은 Python 3.12.13, PyTorch 2.11.0 및 CUDA 12.8 환경에서 수행하였다. 학습에는 NVIDIA GeForce RTX 3070 Ti (NVIDIA, Santa Clara, CA, USA)를 사용하였다.
개체 식별 및 신규 개체 등록 성능 평가
개체 식별 성능은 평가 이미지에서 예측한 개체 ID와 실제 개체 ID의 일치 여부를 기준으로 평가하였다. 평가 이미지가 입력되면 MobileNet V3 기반 특징 추출 모델을 이용하여 256차원의 안면 특징 벡터를 추출하였다. 이후 평가 이미지의 특징 벡터와 Representative-feature database에 저장된 모든 개체의 Representative feature 간 Cosine similarity를 각각 계산하였다. 본 연구의 성능 평가는 평가 이미지가 데이터베이스에 등록된 개체 중 하나에 속한다고 가정한 개체 식별(identification) 조건에서 수행하였다. 따라서 두 이미지가 같은 개체인지 또는 다른 개체인지를 판정하는 verification 방식과 달리, 동일 개체 여부를 판단하기 위한 고정 유사도 임계값은 설정하지 않았다. 각 평가 이미지에 대해서는 계산된 Cosine similarity 값 중 가장 큰 값을 보인 Representative feature의 개체 ID를 최종 예측값으로 결정하였다. 즉, Cosine similarity는 동일·상이 여부를 결정하는 절대 기준이 아니라, 등록된 후보 개체들 중 입력 이미지와 가장 가까운 대표 특징을 선택하기 위한 비교 점수로 사용하였다. 이후 최종 예측 ID와 실제 ID가 일치한 경우를 정분류로 간주하고, 이를 기준으로 개체 식별 정확도를 산출하였다.
개체 식별 정확도는 전체 평가 이미지 중 예측 ID와 실제 ID가 일치한 이미지의 비율로 정의하였으며, 식 (3)과 같이 계산하였다.
Where is the number of images for which the predicted ID matches the ground-truth ID, and is the total number of evaluation images.
초기 개체 인식 모델의 성능은 기존 개체 ID 1–40의 평가 이미지를 대상으로 산출하였다. 신규 개체 등록 성능은 초기 학습에 포함되지 않은 신규 개체 ID 41–72를 대상으로 평가하였다. 신규 개체의 경우 등록 이미지에서 Representative feature를 구성한 뒤, 별도로 분리된 평가 이미지에 대해 식별 정확도를 산출하였다.
등록 조건별 성능을 비교하기 위해 Average accuracy와 New-cattle accuracy를 사용하였다. Average accuracy는 해당 등록 조건에서 식별 대상에 포함된 기존 개체와 신규 개체의 전체 평가 이미지를 대상으로 산출한 식별 정확도로 정의하였으며, 식 (4)와 같이 계산하였다.
Where is the average accuracy, is the number of correctly identified images among all evaluation images, and is the total number of evaluation images for all registered cattle.
New-cattle accuracy는 초기 학습에 포함되지 않은 신규 개체 ID 41–72의 평가 이미지만을 대상으로 산출한 식별 정확도로 정의하였으며, 식 (5)와 같이 계산하였다.
Where is the new cattle accuracy, is the number of correctly identified evaluation images for newly added cattle, and is the total number of evaluation images for newly registered cattle.
대표 시점 구성별 성능 평가
신규 개체 등록 시 안면 시점 구성이 식별 성능에 미치는 영향을 분석하기 위해, 등록 이미지의 시점 구성에 따른 성능 평가를 수행하였다. 본 연구에서는 초기 학습에 포함되지 않은 신규 개체 ID 41–72를 대상으로 등록 이미지를 구성하였으며, 등록에 사용한 이미지는 신규 개체의 등록 후보 데이터에서 선택하였다. 평가 데이터는 등록 이미지 구성 및 모델 갱신 과정에 사용하지 않고, 신규 개체 등록 이후의 식별 성능 평가에만 사용하였다.
등록 이미지의 시점은 정면, 좌측면 및 우측면으로 구분하였다. 정면 이미지는 두 눈과 코의 중심부가 비교적 대칭적으로 관찰되는 이미지로 정의하였으며, 좌측면과 우측면 이미지는 얼굴 방향에 따라 한쪽 안면 영역이 상대적으로 더 많이 관찰되는 이미지로 구분하였다. 각 시점은 등록 이미지가 신규 개체의 안면 특징을 어느 정도 대표할 수 있는지를 비교하기 위해 사용하였다.
등록 조건은 단일 시점 1-shot 조건과 3-shot 조건으로 구성하였다. 단일 시점 1-shot 조건에서는 각 신규 개체에 대해 정면 이미지 1장, 좌측면 이미지 1장 또는 우측면 이미지 1장을 각각 단독으로 등록하였다. 이를 통해 하나의 안면 시점만으로 신규 개체를 등록했을 때의 식별 성능을 평가하였다.
3-shot 조건에서는 등록 이미지 수를 3장으로 동일하게 유지한 상태에서 시점 구성의 영향을 비교하였다. Random 3-shot 조건은 각 신규 개체의 등록 후보 데이터에서 3장의 이미지를 무작위로 선택하여 대표 특징을 구성하였다. Representative 3-shot 조건은 정면, 좌측면 및 우측면 이미지를 각각 1장씩 포함하도록 등록 이미지를 구성하였다. 이를 통해 등록 이미지 수가 동일한 상황에서, 서로 다른 안면 방향을 포함한 대표 시점 구성이 신규 개체 식별 성능에 미치는 영향을 평가하였다.
각 등록 조건에서 신규 개체별 Representative feature를 구성한 뒤, 평가 이미지의 Embedding vector와 Representative feature 간 Cosine similarity를 계산하여 최종 개체 ID를 예측하였다. 성능은 개체 식별 및 개체 등록 성능 평가절에서 정의한 Average accuracy와 New-cattle accuracy를 이용하여 평가하였다.
Results and Discussion
초기 개체 식별 모델 학습 결과
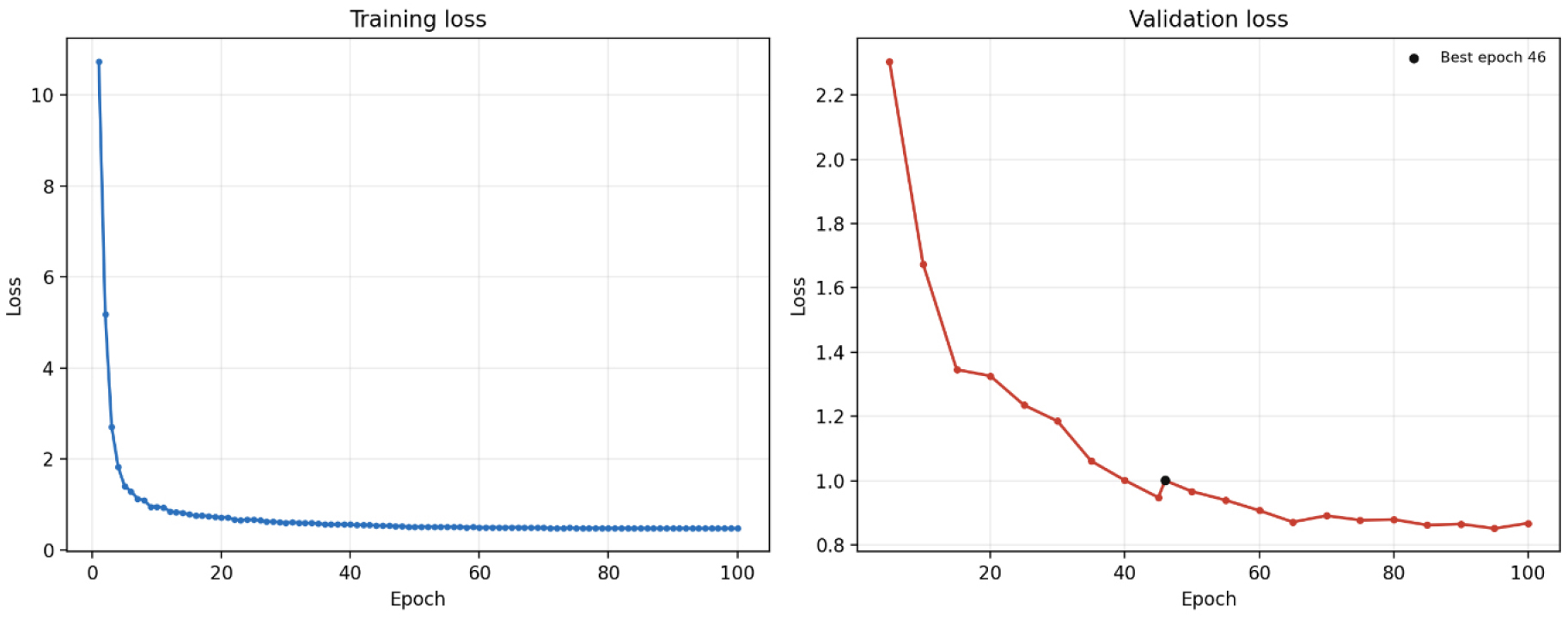
초기 개체 인식 모델은 기존 개체 ID 1–40의 안면 이미지를 이용하여 학습하였다. 학습 과정에서 Training loss와 Validation loss는 Epoch이 증가함에 따라 전반적으로 감소하였으며, Validation accuracy는 학습 초기 빠르게 상승한 뒤 높은 수준에서 수렴하였다. Epoch에 따른 손실 변화는 Fig. 7에 제시하였다.
검증 정확도를 기준으로 최적 모델을 선정한 결과, Epoch 46에서 가장 높은 Validation accuracy가 나타났으며, 이때 Validation accuracy는 98.57%였다. Test dataset에 대한 평가는 검증 정확도를 기준으로 선정된 모델을 이용하여 수행하였다. 선정된 모델의 Test accuracy는 98.68%로 나타났다. 이러한 결과는 MobileNet V3 기반 임베딩 모델이 기존 개체의 한우 안면 이미지에서 개체 구분에 필요한 특징 표현을 효과적으로 학습했음을 보여준다.
대표 시점 구성에 따른 신규 개체 등록 성능
대표 시점 구성에 따른 신규 개체 식별 성능은 Table 3에 제시하였다. 본 실험에서는 초기 학습에 포함되지 않은 신규 개체 ID 41–72를 대상으로, 등록 이미지의 시점 구성이 Representative feature 기반 식별 성능에 미치는 영향을 평가하였다. 이를 위해 신규 개체 등록 과정에서 사용한 두 가지 특징 갱신 조건인 Exemplar-assisted update와 Distillation-assisted update 조건에서 성능을 비교하였다.
Table 3.
Comparison of representative-view registration performance between exemplar-replay and distillation
단일 시점 1-shot 조건에서는 정면 이미지를 등록한 경우가 좌측면 또는 우측면 이미지를 등록한 경우보다 높은 식별 성능을 보였다. Exemplar-assisted update 조건에서 Front 1-shot의 Average accuracy와 New-cattle accuracy는 각각 84.6%와 71.3%로 나타났다. Distillation-assisted update 조건에서도 Front 1-shot의 Average accuracy와 New-cattle accuracy는 각각 85.2%와 72.2%로 나타났다. 반면 좌측면 또는 우측면 이미지만을 등록한 조건에서는 두 특징 갱신 조건 모두에서 상대적으로 낮은 신규 개체 식별 성능이 나타났다. 이는 단일 측면 이미지가 한쪽 안면 정보에 치우쳐 있을 경우 안면의 특징을 충분히 대표하기 어렵기 때문으로 판단된다.
3-shot 등록 조건에서는 정면, 좌측면 및 우측면 이미지를 각각 1장씩 포함한 Representative 3-shot 조건이 가장 높은 성능을 보였다. Exemplar-assisted update 조건에서 Representative 3-shot의 Average accuracy와 New-cattle accuracy는 각각 93.8%와 88.9%로 나타났으며, Distillation-assisted update 조건에서는 각각 94.8%와 91.0%로 나타났다. 동일하게 3장의 등록 이미지를 사용한 Random 3-shot 조건과 비교할 경우, Representative 3-shot 조건은 두 특징 갱신 조건 모두에서 더 높은 신규 개체 식별 성능을 보였다. 이는 신규 개체 등록에서 단순히 등록 이미지 수를 늘리는 것뿐만 아니라, 등록 이미지가 서로 다른 안면 시점을 포함하도록 구성되는 것이 중요함을 보여준다. 특히 정면, 좌측면 및 우측면 이미지를 함께 사용하면 신규 개체의 Representative feature가 다양한 안면 방향의 특징을 반영할 수 있으며, 이로 인해 평가 이미지의 시점 변화에 대해 더 안정적인 식별이 가능했던 것으로 판단된다. 따라서 학습에 포함되지 않은 신규 개체를 소수의 이미지로 등록할 경우, 단일 시점 이미지나 무작위 3-shot보다 좌∙우측 및 정면과 같은 대표 시점 기반 3-shot 구성의 등록 방식이 높은 성능을 도출할 것으로 판단된다.
정면 1-shot 조건에서 좌측면 또는 우측면 1-shot 조건보다 높은 성능이 나타난 이유는 정면 이미지에 좌우 눈, 코, 이마 및 안면 윤곽이 한 영상에 함께 포함되기 때문으로 판단된다. 이러한 특징들은 하나의 이미지로 대표 특징을 구성할 때 개체별 안면 구조를 반영하는 기준 정보로 활용될 수 있다. 반면 좌측면 또는 우측면 이미지는 한쪽 안면 영역을 중심으로 촬영되므로, 평가 이미지의 방향이 등록 이미지와 다를 경우 대표 특징과 평가 특징 간 차이가 커질 수 있다. 이에 따라 단일 시점 등록 조건에서는 정면 이미지가 좌측면 또는 우측면 이미지보다 신규 개체의 대표 특징 구성에 유리함을 확인할 수 있다.
Representative 3-shot 조건과 Random 3-shot 조건의 차이는 등록 이미지의 시점 구성에 있다. Random 3-shot은 등록 후보 데이터에서 3장의 이미지를 무작위로 선택하는 조건이므로, 동일한 방향 또는 유사한 자세의 이미지가 중복될 수 있는 반면, Representative 3-shot은 정면, 좌측면 및 우측면 이미지를 각각 1장씩 포함하도록 구성하였다. 따라서 Representative 3-shot에서는 신규 개체의 대표 특징이 여러 안면 방향에서 관찰되는 특징을 함께 포함할 수 있으며, 평가 이미지의 시점이 달라지는 경우에도 입력 특징과 등록 특징 간 차이를 줄일 수 있다. 이러한 결과는 신규 개체를 소수 이미지로 등록할 때 등록 이미지 수뿐만 아니라 시점 구성을 고려하는 것이 중요함을 보여준다.
Feature-update 조건 간 비교에서는 Representative 3-shot 조건에서 Distillation-assisted update가 Exemplar-assisted update보다 높은 성능을 보였다. Distillation-assisted update는 이전 모델의 출력과 특징 표현을 기준으로 신규 개체 등록 과정에서 기존 임베딩 공간의 변화가 커지지 않도록 학습을 유도한다. 이에 따라 기존 개체에 대해 형성된 특징 공간을 유지하면서 신규 개체의 대표 시점 특징을 반영하는 데 유리했던 것으로 판단된다. 반면 Exemplar-assisted update는 기존 개체의 일부 이미지를 신규 개체 등록 이미지와 함께 사용하는 방식이므로 기존 정보를 직접적으로 포함할 수 있으나, 본 연구에서 사용한 exemplar 수가 제한되어 기존 개체의 다양한 촬영 조건과 특징 분포를 모두 반영하기에는 한계가 있을 수 있다. 따라서 대표 시점 기반 등록 이미지와 distillation 조건을 함께 적용한 경우, 신규 개체의 안면 방향 변화를 반영하면서도 기존 특징 공간의 안정성을 유지하는 데 효과적이었던 것으로 판단된다.
오분류 사례 및 원인 분석
오분류 사례를 확인한 결과, 일부 평가 이미지에서는 등록 이미지와 다른 촬영 구도 및 안면 방향 변화로 인해 개체 식별에 필요한 안면 특징이 충분히 표현되지 않는 경우가 나타났으며, 대표적인 사례는 Fig. 8에 제시하였다. 예를 들어 얼굴이 화면에 크게 포함된 정면 이미지는 눈, 코 및 안면 윤곽의 위치 관계가 등록 이미지와 다르게 표현될 수 있으며, 머리를 숙인 이미지는 이마와 정수리 영역이 넓게 포함되어 눈과 코 주변의 주요 안면 특징이 충분히 반영되지 않을 수 있다. 또한 측면 또는 사선 방향으로 촬영된 이미지에서는 한쪽 눈과 한쪽 안면 윤곽만 주로 관찰되어, 정면 또는 대표 시점 기반 등록 특징과의 일관성이 낮아질 수 있다. Fig. 8의 오분류 사례에서 Cosine similarity는 0.45–0.70 범위로 나타났으며, 이는 일부 오분류가 특정 개체와 높은 유사도를 보였기 때문이라기보다 등록된 후보 개체들 중 가장 큰 Cosine similarity 값을 가진 ID가 선택된 결과로 볼 수 있다. 따라서 신규 개체 등록 기반 식별 성능은 등록 이미지의 시점 구성뿐만 아니라 평가 이미지에서 얼굴 영역이 차지하는 비율, 머리 자세 및 측면 회전에 따른 안면 특징 표현의 변화에도 영향을 받을 수 있음을 확인하였다.

Conclusion
본 연구에서는 한우 안면 이미지를 이용한 딥러닝 기반 개체 인식 방법을 제안하였으며, 학습에 포함되지 않은 신규 개체를 소수의 등록 이미지로 식별 대상에 추가할 수 있는지를 평가하였다. 제안 방법은 얼굴 검출, 안면 특징 추출, 대표 특징 구성 및 코사인 유사도 기반 식별 과정으로 구성되며, 실제 농장에서 수집한 영상 데이터를 이용하여 성능을 검증하였다.
초기 개체 인식 모델은 기존 개체 ID 1–40에 대해 높은 식별 성능을 보였으며, Validation accuracy와 Test accuracy는 각각 98.57%와 98.68%로 나타났다. 이는 MobileNet V3 기반 임베딩 모델이 한우 안면 이미지에서 개체 구분에 필요한 특징 표현을 효과적으로 학습할 수 있음을 보여준다.
신규 개체 등록 실험에서는 등록 이미지의 시점 구성이 식별 성능에 영향을 미치는 것으로 나타났다. 단일 시점 1-shot 조건에서는 정면 이미지를 등록한 경우가 좌측면 또는 우측면 이미지만을 등록한 경우보다 높은 성능을 보였다. 또한 정면, 좌측면 및 우측면 이미지를 각각 1장씩 포함한 Representative 3-shot 조건은 Random 3-shot 조건보다 높은 신규 개체 식별 성능을 보였다. 이는 신규 개체를 소수의 이미지로 등록할 때, 서로 다른 안면 방향을 포함한 대표 시점 구성이 개체의 안면 특징을 더 안정적으로 반영할 수 있음을 의미한다.
따라서 본 연구의 결과는 한우 안면 이미지를 이용한 딥러닝 기반 개체 인식이 부착형 장치에 대한 의존성을 줄일 수 있는 비접촉식 개체 식별 방법으로 활용될 가능성을 보여준다. 특히 학습에 포함되지 않은 신규 개체도 대표 시점 기반 등록 이미지를 이용하여 식별 대상에 추가할 수 있음을 확인하였으며, 이는 입식과 출하가 반복되는 축산 현장에서 개체 등록 및 관리의 효율성을 높이는 데 활용될 수 있을 것으로 판단된다. 본 연구는 실제 농장에서 수집한 영상을 기반으로 한우 안면 기반 신규 개체 등록 가능성을 평가하였으나, 데이터 수집 범위가 단일 농장에 한정되어 있어 농장 간 환경 차이에 대한 일반화 가능성은 추가 검증이 필요하다. 또한 축사 구조, 조명 조건, 촬영 장비와 촬영 위치, 개체의 자세 변화 등은 얼굴 검출 결과와 안면 특징 표현에 영향을 줄 수 있으며, 본 연구는 등록 이미지가 확보된 조건에서의 대표 특징 기반 식별 성능을 평가한 것으로 다중 개체가 동시에 출현하는 연속 영상 기반 실시간 모니터링 환경까지 검증한 것은 아니다. 따라서 향후 연구에서는 다양한 농장 및 촬영 조건에서 수집된 데이터를 기반으로 성능 안정성을 평가하고, 실제 운영 환경에서 신규 개체가 반복적으로 추가될 때의 대표 특징 갱신, 등록 안정성 및 식별 성능 변화를 장기적으로 검토할 필요가 있다.
